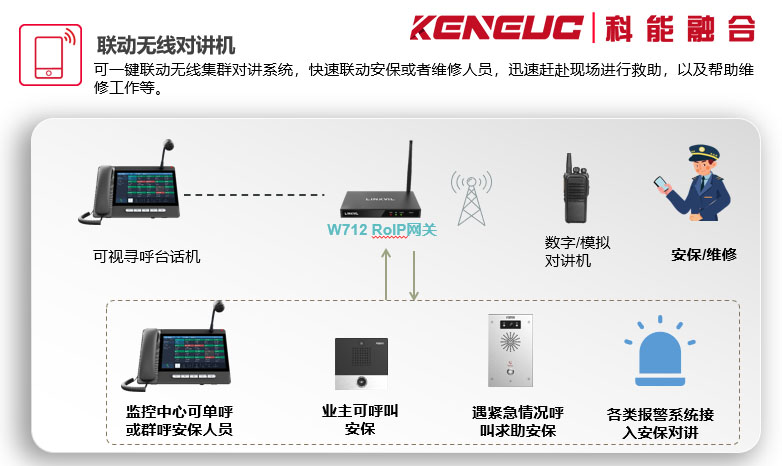
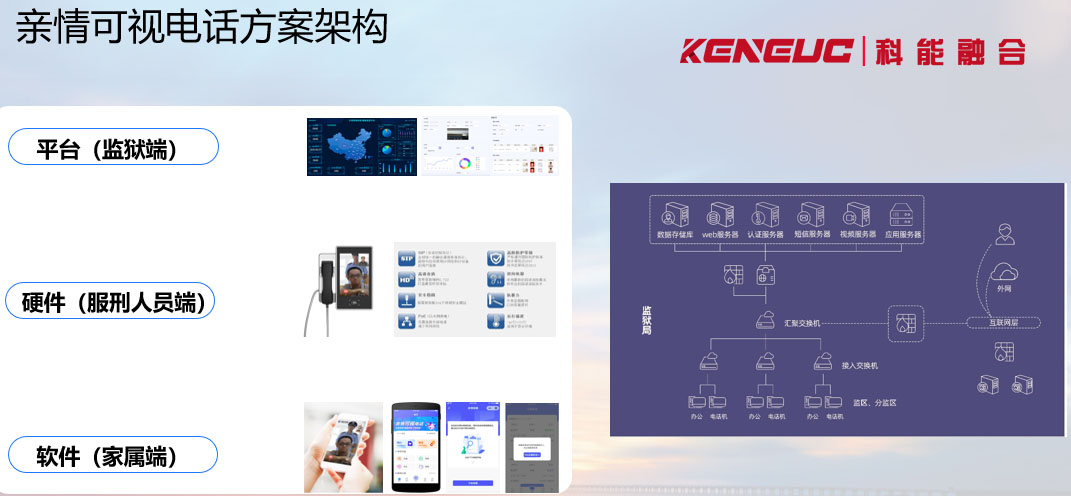
和文件传输、E-mail一样,数字语音也是IP分组应用的一个特例。只不过IP分组里的0和1代表的是人们的语音信息。
许多科学家都认为,人类不同于哺乳动物的根本特征是人类能够相互交谈。由于进化的时问不够长,使得人脑与猿脑还没有根本的差别,对DNA的研究也证明了这一点。人出生后,语言就学得很快。看起来,是人类的语言决定了人类大脑的许多不同之处,使得人们能和亲人对话,而动物却做不到。这一点让科学家感到很奇怪,因为传统的看法是把人类语言归囚于人大脑结构的特别之处而不是相反。人类有更大更复杂的脑是因为人类有更多更复杂的思想需要用语言来表达。例如,人在5岁到11岁之间时,平均每天学习两到三个单词,这正是因为需要学这么多单词来表达自己日益复杂的思想。
不管怎样,只有人类才能把语言当作口常社会交往的基本工具。因为人类社会遍布全球,所以人类需要保持口头的交流,这就促使了全球范围内电话网的建立与发展,而今又是同样的原因使得人们必须把语音引入到全球Internet上。
语音也就是人类语言,是出肺部空气呼出时振动声带而产生,舌和唇对语音的最终形成也有一定作用。技术上把语音分解为音素(译者注:一种特定的语音基本单位)。这种振动的频率(每秒振动次数)在一定的范围之内,对不同的民族来说,频率范围相差不大,不过如果要仔细地考究,就能够根据语言频率范围的细微差异区分开不同的民族。研究表明,如果个儿童到7岁时还没有学会某种特定的准确发音,那么他(她)以后可能再也不会发这个音了。也是因为同样的原因,当一个人在长大以后开始学一门外语时,他(她)讲的外语就像带有很浓重口音。语音可以分为叫做“单词”的语音单元,单词可以组成词组,词组又可以组成句子等。

人们说话所能够听到的距离,不但与声音的强度有关,而且还跟天气的因素有关。有的声音强度高,有的声音强度低,而声音强度是声音的个特征,这个特征对本章来说较为重要。语音是一种传输在空气中的压力波,出嘴发出,耳朵听到。就像发自音乐器材、动物响哮、鸟儿叫的声音样、语音压力波是一种可听波。压力波和在动力系统、无线蜂窝电话系统、电视系统、数据网络等中的电波根本不同。可听波依赖空气传播,所以空气越稀薄(例如在海拔很高的地方),声音强度越小。水的密度很大,所以它传导声音的本领很强,以致人们在空气中能够很容易的分辨出发声位置,然而在水中却不能够,在水中听起来,声音好像米自四面八方。
声音作为一种可听波,属于模拟信息,这就是说,这种波的振幅在最大值和最小值之间变化,可以取其中任意大小的值。声音可以以多种方式来描述,例如摩擦音、唇音等。不过从量化技术上描述声音最简单的方法是把大振幅的声音称作浊音(voicedsounds).而把小振幅的声音称作清音(unvoicedsounds)。在英语中,浊音包括元音,例如“a"o”和“u”等。浊音在喉部产生,直接由声带的位置决定。清音指辅音,例如:“b"、“t”、“v"等等。像空气直接经过声带产生浊音一样,经过舌和唇时产生清音。通常情况下,浊音振幅大约在清音振幅的20倍以上,携带着人类语言的绝大部分能量。但当元音相同时,耳朵分辨一个音节是靠清音的,就像我们在听"belt",“felt”和"melt”时一样。
人们说话所能够听到的距离,不但与声音的强度有关,而且还跟天气的因素有关。有的声音强度高,有的声音强度低,而声音强度是声音的个特征,这个特征对本章来说较为重要。语音是一种传输在空气中的压力波,出嘴发出,耳朵听到。就像发自音乐器材、动物响哮、鸟儿叫的声音样、语音压力波是一种可听波。压力波和在动力系统、无线蜂窝电话系统、电视系统、数据网络等中的电波根本不同。可听波依赖空气传播,所以空气越稀薄(例如在海拔很高的地方),声音强度越小。水的密度很大,所以它传导声音的本领很强,以致人们在空气中能够很容易的分辨出发声位置,然而在水中却不能够,在水中听起来,声音好像米自四面八方。
声音作为一种可听波,属于模拟信息,这就是说,这种波的振幅在最大值和最小值之间变化,可以取其中任意大小的值。声音可以以多种方式来描述,例如摩擦音、唇音等。不过从量化技术上描述声音最简单的方法是把大振幅的声音称作浊音(voicedsounds).而把小振幅的声音称作清音(unvoicedsounds)。在英语中,浊音包括元音,例如“a"o”和“u”等。浊音在喉部产生,直接由声带的位置决定。清音指辅音,例如:“b"、“t”、“v"等等。像空气直接经过声带产生浊音一样,经过舌和唇时产生清音。通常情况下,浊音振幅大约在清音振幅的20倍以上,携带着人类语言的绝大部分能量。但当元音相同时,耳朵分辨一个音节是靠清音的,就像我们在听"belt",“felt”和"melt”时一样。
图2-1描述了在一个模拟声波中浊音与清音的振幅情况。图中把压力波看成与时间相关的波形,这是一个很普通的实例。其他的语言发音与此不同,但主要都是由喉腔或口腔发出的。这种模拟语音振幅的范用在现代语音数字化技术中是一个重要的特征。不过,在发音时不能仅仅根据音标,例如在英语单词"skate”中的爆破音"k”和"kate”中的清音“k”是完全不同的。
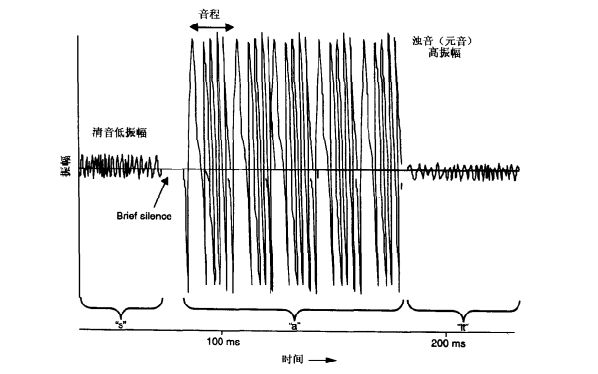
图2-1 英语单词“salt”的发音波形
因为声带的振动是很稳定的,所以如图2-1一样,浊音的波形也很规则。另一方面,清音的波形则更具有随机性和不可预测性,这是因为在发音过程中,口型还可以变换。这些观察结果在现代语音数字化技术中也很重要。
声音波形按音程重复,音程大小因人而异,尤其是在男性和女性之间差别更为显著。男性说话时其音程在5-20ms之间,而女性说话时却在2.5~10ms之间。浊音持续100~125ms,于是一个简单的浊音能到5至50个音高。让人奇怪的是,仅仅要听懂一个语音,并非所有的音程都必不可少,而且人们能够比发出声音更快地听懂某个声音。在一些电视商业中.把一些重复的音程从声音中去除掉,以使速度加快。结果发出的声音,听起来有些怪怪的,但是却说不出怪在哪儿。
再把话题转向电话发明之前,有关人类语音还有一个重要特征需要讨论。这就是在人类语音交流过程中静音也起着重要的作用。几乎在交谈中的任何时刻,听话的人几乎都是完全沉默的,不说话或者简短的一两个字是为了让说话的人知道他(她)正在认真听或者已经听懂,并让说话的人继续说下去。这种反馈的词语在两人交谈时频繁用到,有时当一个人向群听众演讲时听众甚至根本什么话也不说。
此外,在一个句子或一个较长词组说完之后,说话的人还要呼吸,此时也是静音的一个来源。还有在构成,个词组的两个单词的发音之间甚至,在一个多音节单词的两个音节之间也有静音。
在一个典型的两人交谈中,一个人或另一个人发声的时间占40%,而足有50%的时间来自于一个人的静听,另外10%的时间则来自句句之间词词之间和音节与音节之间的停顿。在打电话时,我们可以听到一些背景噪音,并不是明显的噪音源如电视、收音机等发出的噪音,而是一些持续的音量较低的噪音,我们把这种持续的背景噪音称作环境噪音。这种环境噪音的持续存在让电话两端的人在没人说话时也知道电话始终是通的而没有突然断线。
人类语言可以概括出以下三个主要特征:
(1)语音是由高幅声波和低幅声波混合而成;
(2)语音是由规则可预测声波和不规则不可预测声波混合而成;
(3)在双向的交谈中,儿乎有60%的时间是被静音占用。
任何一个语音数字化技术都必须考虑这三个语音的特征。如果有两种语音数字化技术,前一个只考虑了其中某一个特征,而后一个则同时考虑了这三个特征,那么可以断定,后一种方法一定优于前一种方法。