当输入模拟波形是调制解调器信号、传真机信号或任意语音时,采用波形编码的效果最好。波形的形状越多,变化越没规律,就越有必要在量化噪声限制范围内尽可能贴切地模拟输入波形。
不过,如果假定输入波形仅限于人的语音,为了进一步降低必需的数字语音比特率,还能除去更多的冗余吗?事实上,在语音中还有许多冗余,根据这一特性,在语音数字化过程中可以使其速率降至2.4kbit/s。
声码器:对于模拟波形的信源特点人们作出了特定的假设,这些假定有:人的语音完全由清音和浊音组成,而且浊音和清音都有各自持续的时,间;不可能成串地出现许多清音和浊音;浊音中含有被称作“音程”的重复,形式,等等。根据这些假设,产生了被称为“源编码”的语音编码技术。
声码器:对于模拟波形的信源特点人们作出了特定的假设,这些假定有:人的语音完全由清音和浊音组成,而且浊音和清音都有各自持续的时,间;不可能成串地出现许多清音和浊音;浊音中含有被称作“音程”的重复,形式,等等。根据这些假设,产生了被称为“源编码”的语音编码技术。
这些特点使我们能够对语音进行预测。换句话说,如果一个说话人正在发出浊音,那么他(或她)很快就会发出清音。一旦有一个音程被检测出,就有理由预测它会重复出现三到四次。源编码或混合编码的实质就在于对语音进行预测,如今这两种编码方法都在VoIP中得到普遍运用。采用源编码或混合编码的设备称作语音编码器或简称为声码器。采用声码器这一名词是为了表明这种方法仅适用于语音的数字化,要复制任意的波形,就得采用编码解码器。
在实践中,预测编码把语音波形描述为带有数个参数的模型。人们根据预测编码的特定规则设计出某种预测算法,信源和信宿的语音编码器都采用这一算法。发端和收端之间所要传送的是预测波形,与实际波形不同(不过有可能出现这种情况:当我们以为说话人会停止发出清音时,他们不但没有停下,反而继续发出清音!)。只要预测器能够很好地模拟说话人的发音机制,就可用许多参数值来表示这种体现波形差异的信息,从而天大减少发送语音的比特数。
既然源编码有利于增加网络的容量,为什么多年前不使用它呢?这是因为声码器的成本较高,把它缩减比特长度的优点给抵销了。波形编码简单而快捷,源编码却不然,它必须对输入波形进行分析,还必须调整和发送参数。预测是发送器和接收器的基础,它必需连续地工作并在发送器和接收器之间保持同步。所有这些需要大容量存储器,对声码器芯片的处理能力要求很高,而且声码器中的软件相当复杂。
直到80年代后期,声码器技术一直都很昂贵而且原始。声码器产生的声音尽管清晰可懂,但听起来却很机械化且感觉是人工合成的。得克萨斯仪器公司的老式“说话拼读”玩具内有一个芯片式的声码器,一按按钮,它就会把存在存储器中的比特以语音的形式发送出来。但是,除非迫不得以,没有人会愿意在电话中用那种方式交谈。
现有几种形式的声码器,它们都假定语音通过一个线性系统(例如,个输出等于输入叠加的系统就是线性系统)产生,且人的声道正是这样个系统。线性系统不时地受到一系列脉冲的激励,它根据音程来判断输入的声音是不是语音。
所有的线性系统都用不同的技术来模仿人的声道及其参数,所采用技术的不同形成了不同的声码器。但是它们的目的都是产生比特流,使得声音听起来与声源差不多,而不关心输出波形与输入波形到底有几分相似(这正是声码器听起来很不自然,却仍旧好懂的原因)。发送器分析输入的语,音并决定模型参数和激励,接收器则合成语音。
声码器质量不尽如人意是因为所用的算法性能简单。所有的声音不是高幅就是低幅,在两者之间却什么也没有。更糟的是,人耳对浊音的音高十分敏感,但是所有的声码器的注意力都集中在音程上,且至今也未令人满意地解决好音程这个问题。声码器对差错很敏感,这些差错是由于声道模型参数的计算问题,以及线路上的比特差错而产生的。
在语音和音乐合成器中都使用声码器,但这里的讨论只限于它在电话中的应用。关于声码器的构思早在1939年就有了,但只是简单的通道声码器;与此同时,数字语音也诞生了。注意到耳朵对较小的相位失真并不敏感,信道声码器把语音分成20ms长的一些小段,它只关心各段的幅度大小,最后产生2.4kbit/s的语音。对这种声码器改进后形成同型性声码器,它把音高信息加入了幅度之中,付出的代价是把比特率提高到4kbit/so如果芯片处理能力有了质的飞跃,还有一种共振峰声码器来处理语音,理论上可以获得1kbit/s或更低速率的语音。就有如语音的音程一样,共振峰也是语音的一个特征。然而,在实际中难以精确地测定语音共振峰,这使得共振峰声码器很难普及。
在80年代初期,许多声码器用线性预测编码(LPC)获得了2.4kbit/s的低速率。在这种编码方法中,每个语音样值都被假定是先前多个样值的线性组合,LPC机的名字即由此而来。发送器先对一小块20ms的语音进行存储、分析,再确定预测系数,并把量化后的系数传送给接收器。不断到达的语音信号被送入一系列的电路中以计算出预测误差(或称为残差)。在接收器一端所听到的声音就由这些信息产生的。
即使在今天,传统声码器产生的声音听起来仍旧很不自然。之所以如此是因为,单纯源编码器的工作效果取决于所用的声道模型与输入语音信号的相似程度如何。这样,要产生一个同样适用于男人和女人,或是老人和年轻人的语音预测模型是十分困难的。在世界范围内语言种类繁多,有的喉音较重(即带有粗厉刺耳的辅音,比如说德语),有的声调很高(如夏威夷的土著语言),如何找到一种适用于多种语言的方法是一个至今还未解决的问题。
混合编码:大多数现代的编码解码器采用混合编码的方法来解决不同人之间,不同语言之间的语音差异问题。混合编码集波形编码和源编码的特点于一身,在突破16kbit/s障碍的同时获得了低至2.4kbit/s(可望不久将降至1kbit/s),可接受的语音质量。单纯源编码器在这些低比特率上能产生可懂的语音,但无论比特率如何,它所产生的语音听起来都不自然。
现在已有几种形式的混合编码器(混合法特意使用编码解码器这一术语来给其编码器命名,但有时仍把它称作声码器)。但是,最成功且使用最广泛的当属时域合成分析(AbS)编码解码器。这种编码解码器使用与LPC机声码器相同的线性预测声道模型,不过AbS使用激励信号能够更好地反映原始波形的真实特性,而不是仅把一切语音都分为浊音和清音两个成分。
AbS编码解码器出现在1982年,当时被称作混合脉冲激励(MPE)编码解码器。随后的产品是规则脉冲激励(RPE)编码解码器和今天在VoIP上很普及的码激励线性预测(CELP)编码解码器系列。MPE在10kbit/s的速率上有不错的语音质量,而RPE工作在13kbit/s的速率上。RPE用于泛欧无线全球移动通信系统(GSM)数字网络中。
与声码器一样,所有的Abs编码解码器也得先把语音分成一些20ms的组块,这些语音组块被称作一顿,不过顿长是可变的。接着Abs编码器采用与声码器相类似的方法对顿参数和激励信号进行分析,然后还要进行综合分析。在发送端,编码器实际上先把输入顿的许多不同表征特性综合在一起,再把每个激励信号与输入顿进行比较,做法和其自身就像接收器一样。当然,这就需要很强的处理能力来进行实时处理,这种“闭环”编码是Abs编码解码器与众不同的特征。
为了使合成过滤器(对误差进行衡量)能够处理每个可能的激励信号芯片所需的时间与开销是非常大的。必需找到一些措施来降低复杂度,但这意味着或是通过辆牲一些语音质量来降低所需的比特率,其代价是提高比特率或者牺牲一些语音质量,或是两者都要损失。出于这个原因,这种技术只能获得10kbit/s左右的语音。
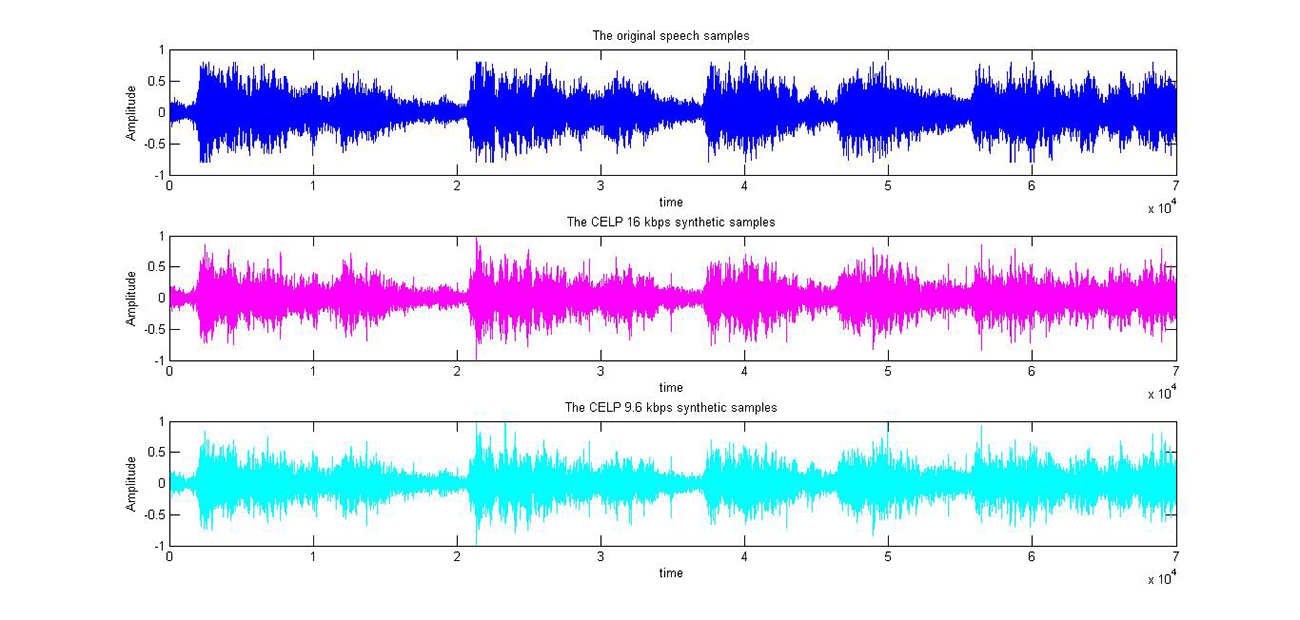
CELP出现于1985年,它的结构十分复杂。实际上,由于它太复杂,以致于不能在当时的大多数处理器上运行。如果在一台Cray-1超级电脑上采用CELP最初的完全算法,需要125s才能产生1s的数字语音。这以后,处理器的处理能力不断提高(当时的Crag-1的处理能力儿乎只相当于现在的一台视频游戏机),而且CELP的复杂性也不断降低,这意味着已经可以在DSP芯片上实现CELP了。基于CELP产生了几个标准,它们的运行速率为16kbit/s至4.8kbit/s。在16kbit/s时,CELP语音质量与64kbit/s的PCM一样好,不过理所当然地,CELP语音设备一般要比PCM的贵。
工作在4.8kbit/s速率下的CELP编码解码器已制造出来了,当前的目标是突破2.4kbit/s的障碍。大多数新方法把输入的语音顿分为浊音、清音和过渡类型。每一种类型都有自己的精密编码器和白己的一套规则。比如说,清音没有固定的音程和音高,于是不需要对它进行长期预测。现有一种最新的CELP技术,通常称作多带激励(MBE)编码解码器。还有-种被称为波形插补(WI)编码解码器的方法与CELP一起使用,不过它与AbS和CELP系列没有直接关系。
今天,CELP系列包括如下的成员:ACELP(代数码激励线性预测编码)、MP-MLQ(多脉冲最大可能量化)、LD-CELP(低时延CELP,用来减少CELP数字化所需的处理时间)和CS-CELP(固定结构CELP)。所有这些都是基本的CELP的改进。以ACELP和MP-MLQ为例,它们通常采用30ms顿并提前7.5毫秒进行预测比较,不过有关它们的细节并不是这里所关心的。