参数编码特又称声码器(Vocoder),它的原理和设计思想和波形编码完全不同。波形编码的基本思路是忠实地再现话音的时域波形,为了降低比特率,可以充分利用相邻抽样点之间的信息冗余性,对差分信号进行编码,在不影响话音质量的前提下,比特率可降至32kbit/s。在话务过载的情况下,还可降质使用24或16khit/s编码,但要进一步降低比特率就有困难了。
参数编码根据对声音形成机理的分析,着眼于构造话音生成模型,该模型以一定精度模拟发话者的发声声道,接收端根据该模型还原生成发话者的音素,在频域上该模型就对应为具有一定零极点分布的数字滤波器。编码器发送的主要信息就是该模型的参数,相当于话音的主要特征,而并非具体的话音波形幅值。而且由于话音信号变化是缓慢的,一个音素要持续相当长一段时间(相对于抽样周期而言),因此模型参数的更新频度较低,不但可以利用抽样值间的相关性,还可以充分利用帧与帧之间的信息冗余性以及更长时间段中的音源信息冗余性,有效地降低编码比特率。因此,目前小于16kbit/s的低比特率话音编码都采用参数编码。它在移动通信、多媒体通信和IP网络电话应用中起到重要的作用。
需要指出的是,虽然参数编码和波形编码的原理完全不同,但是归根结底信息都取自于对抽样值的分析计算,为了去除冗余信息都需对差分信号(或称残差信号)进行处理,因此在技术上两者并无明显的界线,许多技术,如线性预测、自适应预测、矢量量化等既可用于参数编码,也可用于波形编码。
不难理解,为了掌握参数编码原理,首先必需懂得话音特征分析和声音形成机理。
声音形成机理
话音形成的大致过程可由图3.8表示:
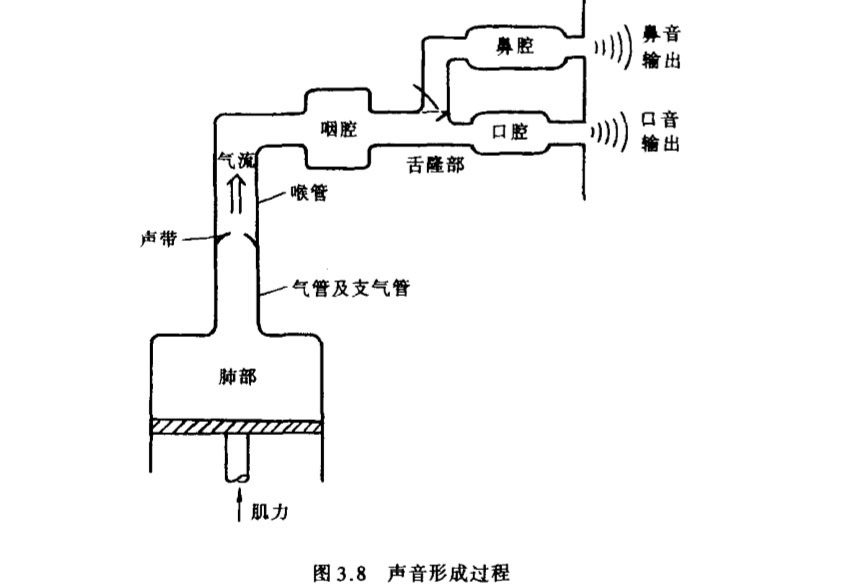
从肺部压出的空气由气管到达声门,气流流经声门时形成声音,然后再经咽腔,由口腔或鼻腔送出。其中咽腔和口腔、鼻腔构成由多节声管组成的声道,当腔体呈不同形状,舌、齿、唇等处于不同位置时,相当于形成一个具有不同零极点分布的滤波器,气流通过该滤波器后产生相应的频响输出,从而发出不同的音素。
音素可分为两类。伴有声带振动的音称为浊音(VoicedSound),它包括元音、浊辅音、半元音和鼻音。声带不振动的音称为清音(unvoicedsound),包括清辅音和气音。由于声带振动有不同的频率,因此浊音就有不同的音调,称之为基音频率。男性基音频率范围一般为50-250Hz,女性基音频率一般为100-500Hz。另外气流压出的不同强度就对应为声音的音量大小。
从频域角度看,浊音气流流经声道后,其幅频特性在声道的滤波作用下将呈现两个显著的特点。一是幅频频谱的包络有几个明显的局部最大值,称之为共振峰。在这些频率点处,反射波相互迭加,声波能量加强。二是频谱的精细结构呈现周期性,即每隔一定频率间距出现一个峰值,该间距对应的就是基音频率。而且频谱的能量主要集中在低频段,超过4kHz后频谱迅速下降。
图3.9示出元音[A]的对数振幅频谱:
![元音[A]的对数振幅频谱](/uploads/allimg/200130/1-200130122023X1.jpg)
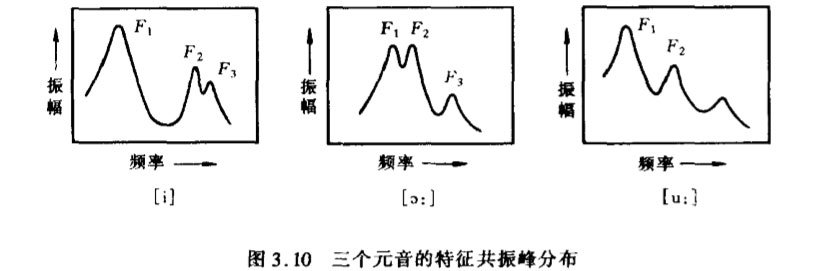
由图可见,其包络有4个共振峰,其频率分别为F1=550Hz,F2=1.15kHz,F3=2.45kHz和F4==3.6kHz。另外,该频谱显示在0-1500Hz之间大致有12个峰值,表示基音频率约为125Hz。分析表明,对于浊音尤其是元音,频谱的前3个共振峰为特征共振峰,据此可以识别不同的元音,这一特性可以应用于语音识别和语音压缩编码,它表明声道的基本特性可以用一个全极点滤波器近似模拟。图3.10示出[i]:[o:]、[u:]三个元音的特征共振峰。由于共振峰可以识别音素,而一个音素持续的时间相对较短(音节时间),因此我们说频谱包络反映了话音的短时相关性。而发话者基音频率的变化则比较缓慢,因此频谱的精细结构反映了话音的长时相关性。
清音的频谱特性和浊音有很大差别。因为声带没有振动,因此频谱形状没有周期性,峰值的分布也没有明显的规律,整个频谱相对比较平坦,反映了清音音源类似于白噪声。而且清音的频谱能量集中在高频区,即使超过8kHz频谱也没有显著的下降。
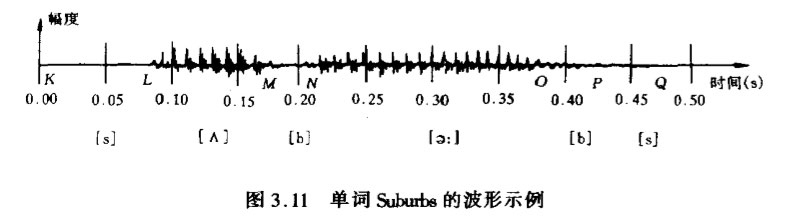
在时域上,话音波形也反映出上述浊音和清音的特点。图 3.11示出单词suburbs的波形图。由图可见,清音[s]的波形类似于白噪声,振幅很弱;元音[A]和[a:J具有明显的周期性,且具有较强的振幅。元音[A]从0.10-0.15s间大致有6个周期,对应的基音频率约为120Hz。
根据上述分析可得话音生成的数字模型如图3.12所示。它由声源和声道两部分组成。声源包括激励信号和增益G。浊音的激励源为一串周期性的脉冲,脉冲周期即基音周期;清音的激励源为噪声信号。增益反映信号的强弱.开关S则表示清/浊音判决。声源决定了话音信号频谱的精细结构。声道由声道滤波器和辐射滤波器组成,前者可用全极型或极零型滤波器近似,后者反映了气流经嘴唇往外辐射后的衰减,衰减幅度为倍频程6dB。一般将二者合为一个滤波器,它决定了话音频谱的包络特性。
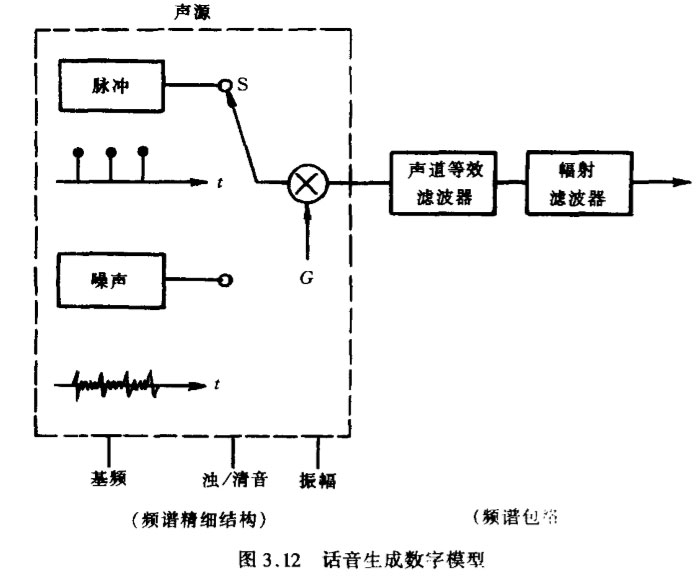
上述数字模型表明声码器进行话音编码需包含以下4类参数:
.若于定义声道共振特性的滤波器系数。
.一个二进制参数,指明激励源是清音还是浊音。
.激励游能量值。
.基音周期值(仅对浊音有意义)。
由于音素至少持续儿十毫秒,因此可以近似认为在短时间内上述数字模型为一个线性时不变系统,主声道参数只要计算一次即可适用于所有抽样值。这段时间就称为-帧,通常为IO-30ms。也就是说,利用话音频谱的短时相关性可以有效地降低编码的比特率。基音周期反映话音信号的长时相关性,利用它表征激励源特性可以进一步降低编码速率。从图3.11所示话音波形可知,基音周期通常比帧长还要短,因此基音周期参数更新周期一般要小于帧长。




