PCM虽然能够提供相当好的长途通信级话音质量,但是其速率过高,尤其在多媒体应用以及在共享信道的数据网中应用时,采用PCM传送话音占用的网络带宽资源嫌过高。为此,人们提出了许多改进技术,以降低话音编码的速率,或者说在同样的码率下可以进一步提高话音的质量。
1.差分编码技术
降低编码比特率的基本思路是利用话音抽样信号之间的相关性。分析表明,话音波形中有很多的冗余信息,作为信息冗余的度量,相邻8kHz抽样值之间的自相关系数一般为0.85以上。由此可知,相邻抽样值之差一般很小,其包含的信息量远小于抽样值本身。因此一个自然的想法就是设计一种编码方法,对此差值进行编码,而不是对抽样值本身进行编码,这样所需的比特率必然可以下降。这就是所谓的差分脉冲编码(DPCM)。
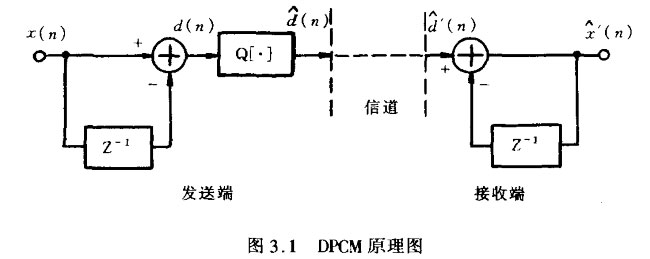
产生差分信号最简单的方法是直接存储前一次的输入样值(例如用抽样保持电路),然后用模拟减法器获得差值,经量化编码后发送出去。解码器则作相反的处理恢复原信号。其原理图如图3.1所示
用Z变换考察各点信号的时域关系,有:
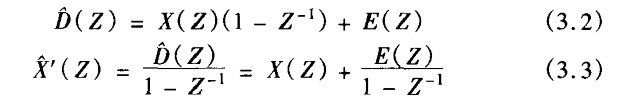
式中,E(Z)为量化噪声的Z变换,且假设信道无失真。由式(3.3)知,在接收端量化噪声被累积,且迭加在输出信号中。从时域角度看就是每次量化噪声信号均被记忆下来,然后迭加到下一次输出中去。如果量化噪声始终是同一方向的话,会使输出信号越来越偏离正常信号,显然这是不允许的。因此实际DPCM编码器是通过反馈的方式由差分编码值重构生成前一次抽样值的,其结构如图3.2所示。
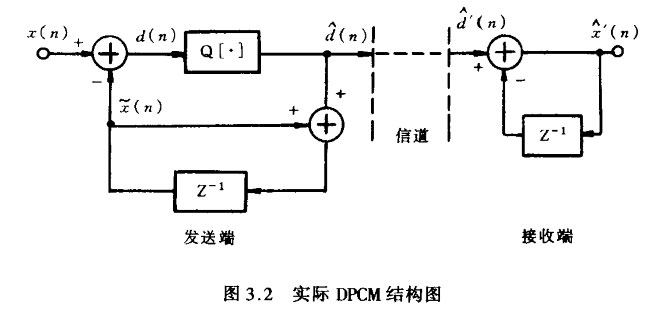
由图可知,若某一时刻量化噪声信号为正,则它将使重构的抽样值增大,从而使下一时刻的差分信号变小,如此即可有效地抵消上一次量化噪声的影响。从Z变换也不难得出同样的结论。由图可得,反馈重构信号为:
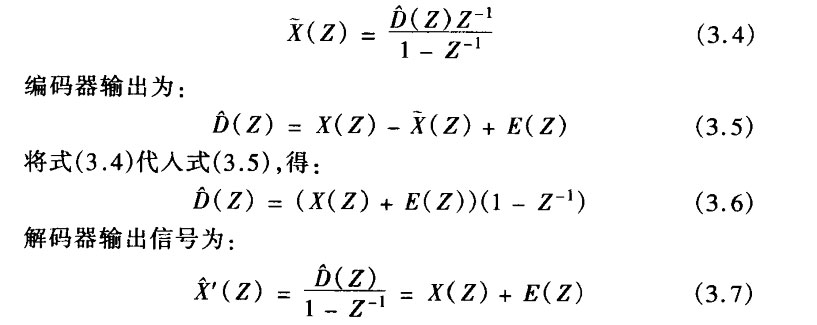
即,已消除量化噪声的积累。
上述基本的差分编码只利用了当前时刻抽样值和上一时刻抽样值之间的相关性,实际上当前输人值不但和上一时刻样值有关,还和前面若干个抽样值都有关,为了充分利用话音波形中固有的信息冗余,进一步降低编码比特率,我们可以将前若干个抽样值的线性组合作为当前输入信号的预测值,由此求得差分信号为:
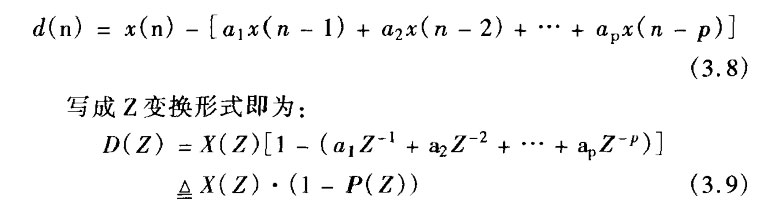
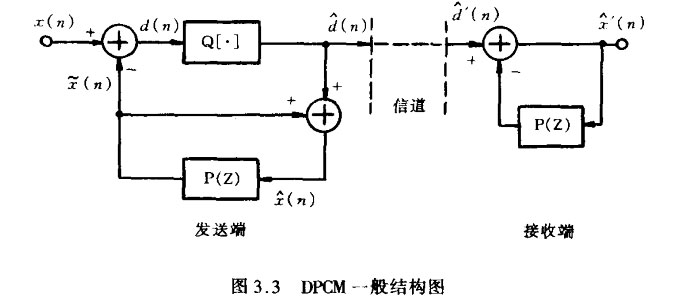
式中,P(Z)称为线性预测多项式,llj称为预测系数。ai的选取应使差分信号(即预测误差)的方差为最小。显然,预测多项式阶数越高,预测误差就越小,相应编码比特率也可越低。上述基本差分编码相当于最简单的预测系数恒为1的1阶线性预测。分析表明,如果预测系数a;取为常数,则采用3阶线性预测可有效地提高编码效率,阶数再高改善效果已不明显。
图3.3为采用线性预测的DPCM一般结构图。和基本差分编码一样,为了避免量化噪声的积累,预测值由反馈回路产生,也就是说,预测多项式中用到的前面各次抽样值都是由预测误差量化值反馈生成的重构值,并非真实的历史抽样值。
从能量角度看,采用差分编码后,由于差分信号比原信号功率减小,其量化限幅电平相应可降小。这样在量化电平数不变的条件下,差分量化器的量化阶距就比原信号的量化阶距要小,即量化噪声减小。因此差分编码的信噪比将比直接对原信号编码的PCM高,由此得到差分增益或称预测增益,其值等于原信号功率和差分信号功率之比。从另一角度说,如保持信噪比不变,则可减小量化器字长,即降低编码比特率。
分析表明,l阶预测DPCM的差分增益可为5dB,可比PCM减少1比特编码长度,即为56kbit/s比特率。3阶预测DPCM能减少1.5-2比特编码长度,即为48kbit/s比特率。
另有一种更为简单的差分编码称为增量调制(DM)。其差分信号也是表示相邻抽样值之差,但是量化值仅用1个比特表示,实际上就是差值的符号。量化步长为固定值L:::..,根据当前输入值比前次值上升还是下降,取差分信号的量化值为今或_L::,,.。这一方法简单,但对信号变化速率大的部分将会产生较大的量化噪声。
2.自适应撮化
由前分析可知,为了获得尽可能小的量化信噪比,应该对小信号采用较小的量化步长,对大信号可采用较大的量化步长。由于对不同讲话者和在不同环境下,话音能量的差别可高达40dB,即使在同一话音中,不同时刻的信号幅度也会有相当大的变化,因此有必要根据输入信号的幅度变化动态地调整量化步长。这样可使量化器范围和输人信号的动态范围相匹配,减小量化噪声,从而进一步降低编码比特率。这就是自适应量化技术。它可用于PCM、DPCM和DM。对于线性恨化来说,只需控制个量化步长即可;对于非线性量化来说,则要根据给定的非线性特性控制多个晕化步长。
话音信号幅度随时间的变化有两种情况。一种是相邻或相近若干抽样值之间的快变化,称之为瞬时变化;另一种是相邻音节之间的慢变化,称之为音节变化。一个音节周期一般为10-20ms。与之相应有两种自适应量化算法,即瞬时自适应法和音节自适应法。其基本原理相同,首先是计算输入话音信号的幅值或方差,然后据此控制量化步长。
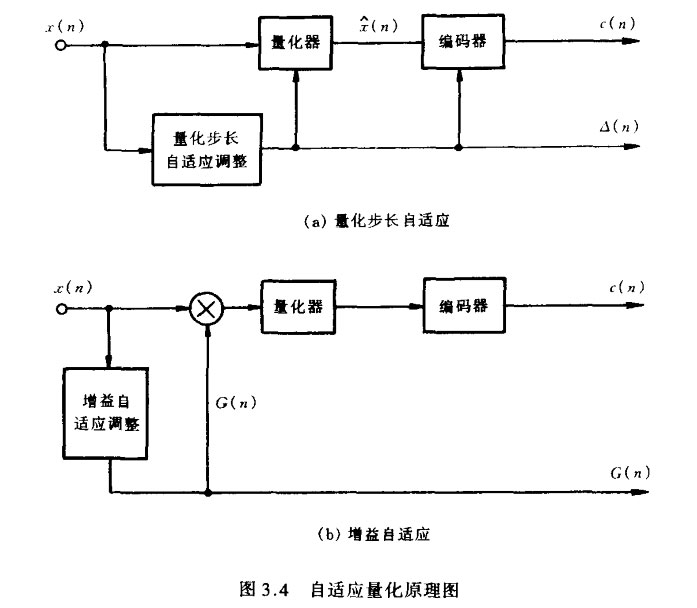
另有一种思路完全不同的自适应量化方法。它不是去调整量化步长,而是采用自动增益控制原理,根据输入话音信号的幅度或方差来调整量化器输入信号的大小。具体来说,就是用算得的话音信号幅值或方差去控制一个时变增益因子G(n),使其随方差成反比例关系变化,然后将输入信号x(n)乘以G(n)后加至量化器,使量化器输入信号方差保持恒定。这样量化步长不用变化,仍然可获得恒定的信噪比。
图3.4示出步长调整和增益调整两种自适应量化的原理图。编码器除了发送编码码字c(n)外,还需发送量化步长L::,,.(n)或增益因子G(n),解码器据此才能恢复原始信号。
3.自适应线性预测
如前所述,差分编码调制之所以能降低比特率的原因是它编码的对象是差分信号,其功率较原信号低。比特率能降到什么程度则取决于预测精度,也就是话音波形信息冗余的去除程度。由于前述差分编码采用的都是固定系数的线性预测器,不能很好地适应话音的不平稳特性,因此即使采用高阶预测,信噪比的改善也很有限,最低比特率只能降至48kbit/s。为此,必须采用自适应技术动态调整预测器系数,才能进一步降低编码比特率。这就是自适应差分脉冲编码调制(ADPCM)技术。一般说来,ADPCM既包含自适应预测,也包含自适应量化,最低比特率可达16khit/s。
自适应线性预测的基本原理是根据话音波形的时间相关性确定预测系数,使差分信号的方差为最小,时间相关性则是以自相关函数来度量的。由于话音信号的自相关函数大体是随音节而变化的,也就是在/个音节时间内自相关函数基本不变,只是从一个音节至另一音节时才有较明显的变化,因此自适应预测都采用音节适应算法。在此,一个音节的时间常称为一帧。
为了计算预测系数,需要设定一个数据取样窗口。设窗口宽度为N,则每帧需用到N个抽样值,利用这些样值估算自相关函数值,并进而计算预测系数。和差分编码类似,这N个抽样值可以直接取自于输入信号,由缓冲寄存器暂存,也可以由量化后的差分信号反馈后重构生成。前者称为前馈(feed-forward)自适应预测,又称开环自适应预测,是根据原始信号调整预测系数的。后者称为反馈(feedback)自适应预测,又称闭环自适应预测,是根据重构信号调整系数的。
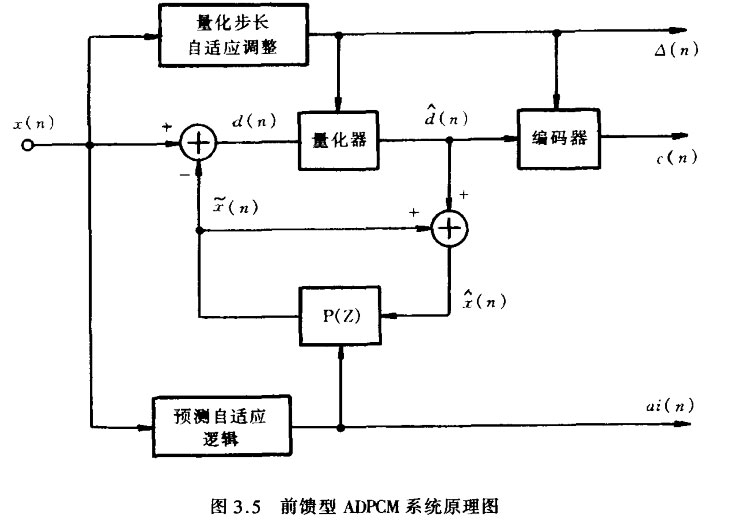
图3.5为前馈型ADPCM系统原理图,其中包括自适应量化。和图3.3比较可知,系统的核心部分和DPCM相同,但是P(Z)的系数受自适应逻辑控制。自适应量化也采用前馈型控制。编码器输出包括3类信息:
·差分信号编码码字c(n)
·预测器系数ai(n)
·量化步长L::,.(n)或者增益因子G(n)
反馈型ADPCM系统的解码器采用和编码器同样的结构和算法,它可以根据输人信号推算出自相关特性和信号方差,从而计算出预测系数和量化步长或增益因子。因此,反馈型系统的好处是只需要传送编码码字c(n),尤需传送预测器系数和量化步长或增益因子,比特率可以降低。但是它有一个严重的缺点,即解码器侧自适应特性对传输误码十分敏感,它将使解码器的预测器和量化器和编码器不一致,从而造成话音失真。一般高比特率系统可采用反馈型自适屯预测,因为其话音编码对传输信道误码的敏感度较低,低比特率系夕允则采用前馈型自适应技术。
根据自适应预测使用的N个抽样值是取自当前帧还是上一帧,又可将自适应预测分为前向预测和后向预测两类。前向预测采用当前帧的样本值算出预测器系数,然后计算当前帧的预测信号,得出差分信号进行编码。其预测精度高,可获得较低的编码比特率,代价是要引人1帧时间的算法时延。后向预测采用上一帧的样本值算出预测器系数,以此预测器计算当前帧的预测信号,它没有算法时延,但预测精度较低。
采用自适应预测技术后,一般都选用高阶预测器,以提高精度。常用的为10-12阶预测器。如果采用后向预测,预测增益可达13dB;如果采用前向预测,预测增益可达20dB以上。